
Core Consultant Prep Quiz
How does Monitoring Console (MC) initially identify the server role(s) of a new Splunk Instance?
The MC uses a REST endpoint to query the server.
Roles are manually assigned within the MC.
Roles are read from distsearch.conf.
The MC assigns all possible roles by default.
A customer has asked for a five-node search head cluster (SHC) but does not have the storage budget to use a replication factor greater than 2. They would like to understand what might happen in terms of the users' ability to view historic scheduled search results if they log onto a search head that doesn't contain one of the 2 copies of a given search artifact.
Which of the following statements best describes what would happen in this scenario?
Which of the following statements best describes what would happen in this scenario?
The search head that the user has logged onto will proxy the required artifact over to itself from a search head that currently holds a copy. A copy will also be replicated from that search head permanently, so it is available for future use.
Because the dispatch folder containing the search results is not present on the search head, the user will not be able to view the search results.
The user will not be able to see the results of the search until one of the search heads is restarted, forcing synchronization of all dispatched artifacts across all search heads.
The user will not be able to see the results of the search until the Splunk administrator issues the apply shcluster-bundle command on the search head deployer, forcing synchronization of all dispatched artifacts across all search heads.
Monitoring Console (MC) health check configuration items are stored in which configuration file?
Healthcheck.conf
Alert_actions.conf
Distsearch.conf
Checklist.conf
What should be considered when running the following CLI commands with a goal of accelerating an index cluster migration to new hardware?

Data ingestion rate
Network latency and storage IOPS
Distance and location
SSL data encryption
Which statement is true about subsearches?
Subsearches are faster than other types of searches.
Subsearches work best for joining two large result sets.
Subsearches run at the same time as their outer search.
Subsearches work best for small result sets.
A customer has been using Splunk for one year, utilizing a single/all-in-one instance. This single Splunk server is now struggling to cope with the daily ingest rate.
Also, Splunk has become a vital system in day-to-day operations making high availability a consideration for the Splunk service. The customer is unsure how to design the new environment topology in order to provide this.
Which resource would help the customer gather the requirements for their new architecture?
Also, Splunk has become a vital system in day-to-day operations making high availability a consideration for the Splunk service. The customer is unsure how to design the new environment topology in order to provide this.
Which resource would help the customer gather the requirements for their new architecture?
Direct the customer to the docs.splunk.com and tell them that all the information to help them select the right design is documented there.
Ask the customer to engage with the sales team immediately as they probably need a larger license.
Refer the customer to answers.splunk.com as someone else has probably already designed a system that meets their requirements.
Refer the customer to the Splunk Validated Architectures document in order to guide them through which approved architectures could meet their requirements.
The customer has an indexer cluster supporting a wide variety of search needs, including scheduled search, data model acceleration, and summary indexing.
Here is an excerpt from the cluster master's server.conf:

Which strategy represents the minimum and least disruptive change necessary to protect the searchability of the indexer cluster in case of indexer failure?
Here is an excerpt from the cluster master's server.conf:
Which strategy represents the minimum and least disruptive change necessary to protect the searchability of the indexer cluster in case of indexer failure?
Enable maintenance mode on the CM to prevent excessive fix-up and bring the failed indexer back online.
Leave replication_factor=2, increase search_factor=2 and enable summary_replication.
Convert the cluster to multi-site and modify the server.conf to be site_replication_factor=2, site_search_factor=2.
Increase replication_factor=3, search_factor=2 to protect the data, and allow there to always be a searchable copy.
What is the primary driver behind implementing indexer clustering in a customer's environment?
To improve resiliency as the search load increases.
To reduce indexing latency.
To scale out a Splunk environment to offer higher performance capability.
To provide higher availability for buckets of data.
In a single indexer cluster, where should the Monitoring Console (MC) be installed?
Deployer sharing with master cluster.
License master that has 50 clients or more.
Cluster master node.
Production Search Head.
A customer has downloaded the Splunk App for AWS from Splunkbase and installed it in a search head cluster following the instructions using the deployer. A power user modifies a dashboard in the app on one of the search head cluster members. The app containing an updated dashboard is upgraded to the latest version by following the instructions via the deployer.
What happens?
What happens?
The updated dashboard will not be deployed globally to all users, due to the conflict with the power user's modified version of the dashboard.
Applying the search head cluster bundle will fail due to the conflict.
The updated dashboard will be available to the power user.
The updated dashboard will not be available to the power user; they will see their modified version.
A customer's deployment server is overwhelmed with forwarder connections after adding an additional 1000 clients. The default phone home interval is set to 60 seconds. To reduce the number of connection failures to the DS what is recommended?
Create a tiered deployment server topology.
Reduce the phone home interval to 6 seconds.
Leave the phone home interval at 60 seconds.
Increase the phone home interval to 600 seconds.
What is the Splunk PS recommendation when using the deployment server and building deployment apps?
Carefully design smaller apps with specific configuration that can be reused.
Only deploy Splunk PS base configurations via the deployment server.
Use $SPLUNK_HOME/etc/system/local configurations on forwarders and only deploy TAs via the deployment server.
Carefully design bigger apps containing multiple configs.
Which of the following processor occur in the indexing pipeline?
Tcp out, syslog out
Regex replacement, annotator
Aggregator
UTF-8, linebreaker, header
Which configuration item should be set to false to significantly improve data ingestion performance?
AUTO_KV_JSON
BREAK_ONLY_BEFORE_DATE
SHOULD_LINEMERGE
ANNOTATE_PUNCT
***A customer has a new set of hardware to replace their aging indexers. What method would reduce the amount of bucket replication operations during the migration process?
Disable the indexing ports on the old indexers.
Disable replication ports on the old indexers.
Put the old indexers into manual detention.
Put the old indexers into automatic detention.
When a bucket rolls from cold to frozen on a clustered indexer, which of the following scenarios occurs?
All replicated copies will be rolled to frozen; original copies will remain.
Replicated copies of the bucket will remain on all other indexers and the Cluster Master (CM) assigns a new primary bucket.
The bucket rolls to frozen on all clustered indexers simultaneously.
Nothing. Replicated copies of the bucket will remain on all other indexers until a local retention rule causes it to roll.
A site from a multi-site indexer cluster needs to be decommissioned. Which of the following actions must be taken?
Nothing. Decommissioning a site is not possible.
Create an alias for where the new data should be sent.
Remove the site from the list of available sites.
Remove the site from the list of available sites and create an alias for where the new data should be sent.
A customer wants to implement LDAP because managing local Splunk users is becoming too much of an overhead. What configuration details are needed from the customer to implement LDAP authentication?
API: Python script with PAM/RADIUS details.
LDAP server: port, bind user credentials, path/to/groups, path/to/user.
LDAP server: port, bind user credentials, base DN for groups, base DN for users.
LDAP REST details, base DN for groups, base DN for users.
A customer has a search cluster (SHC) of six members split evenly between two data centers (DC). The customer is concerned with network connectivity between the two DCs due to frequent outages. Which of the following is true as it relates to SHC resiliency when a network outage occurs between the two DCs?
The SHC will function as expected as the SHC deployer will become the new captain until the network communication is restored.
The SHC will stop all scheduled search activity within the SHC.
The SHC will function as expected as the minimum required number of nodes for a SHC is 3.
The SHC will function as expected as the SHC captain will fall back to previous active captain in the remaining site.
A [script://] input sends data to a Splunk forwarder using which method?
TCP stream
UDP stream
Temporary file
STDOUT/STDERR
An index receives approximately 50GB of data per day per indexer at an even and consistent rate. The customer would like to keep this data searchable for a minimum of 30 days. In addition, they have hourly scheduled searches that process a week's worth of data and are quite sensitive to search performance.
Given ideal conditions (no restarts, nor drops/bursts in data volume), and following PS best practices, which of the following sets of indexes.conf settings can be leveraged to meet the requirements?
Given ideal conditions (no restarts, nor drops/bursts in data volume), and following PS best practices, which of the following sets of indexes.conf settings can be leveraged to meet the requirements?
FrozenTimePeriodInSecs, maxDataSize, maxVolumeDataSizeMB, maxHotBuckets
MaxDataSize, maxTotalDataSizeMB, maxHotBuckets, maxGlobalDataSizeMB
MaxDataSize, frozenTimePeriodInSecs, maxVolumeDataSizeMB
FrozenTimePeriodInSecs, maxWarmDBCount, homePath.maxDataSizeMB, maxHotSpanSecs
A customer has a Universal Forwarder (UF) with an inputs.conf monitoring its splunkd.log. The data is sent through a heavy forwarder to an indexer. Where does the Index time parsing occur?
Indexer
Universal forwarder
Search head
Heavy forwarder
The customer wants to migrate their current Splunk Index cluster to new hardware to improve indexing and search performance. What is the correct process and procedure for this task?
1. Install new indexers.
2. Configure indexers into the cluster as peers; ensure they receive the same configuration via the deployment server.
3. Decommission old peers one at a time.
4. Remove old peers from the CM's list.
5. Update forwarders to forward to the new peers.
2. Configure indexers into the cluster as peers; ensure they receive the same configuration via the deployment server.
3. Decommission old peers one at a time.
4. Remove old peers from the CM's list.
5. Update forwarders to forward to the new peers.
1. Install new indexers.
2. Configure indexers into the cluster as peers; ensure they receive the cluster bundle and the same configuration as original peers.
3. Decommission old peers one at a time.
4. Remove old peers from the CM's list.
5. Update forwarders to forward to the new peers.
2. Configure indexers into the cluster as peers; ensure they receive the cluster bundle and the same configuration as original peers.
3. Decommission old peers one at a time.
4. Remove old peers from the CM's list.
5. Update forwarders to forward to the new peers.
1. Install new indexers.
2. Configure indexers into the cluster as peers; ensure they receive the same configuration via the deployment server.
3. Update forwarders to forward to the new peers.
4. Decommission old peers one at a time.
5. Restart the cluster master (CM).
2. Configure indexers into the cluster as peers; ensure they receive the same configuration via the deployment server.
3. Update forwarders to forward to the new peers.
4. Decommission old peers one at a time.
5. Restart the cluster master (CM).
1. Install new indexers.
2. Configure indexers into the cluster as peers; ensure they receive the cluster bundle and the same configuration as the original peers.
3. Update forwarders to forward to the new peers.
4. Decommission old peers one at a time.
5. Remove old peers from the CM's list.
2. Configure indexers into the cluster as peers; ensure they receive the cluster bundle and the same configuration as the original peers.
3. Update forwarders to forward to the new peers.
4. Decommission old peers one at a time.
5. Remove old peers from the CM's list.
Consider the scenario where the /var/log directory contains the files secure, messages, cron, audit. A customer has created the following inputs.conf stanzas in the same Splunk app in order to attempt to monitor the files secure and messages:
Which file(s) will actually be actively monitored?
/var/log/secure
/var/log/messages
/var/log/messages, /var/log/cron, /var/log/audit, /var/log/secure
/var/log/secure, /var/log/messages
How could a role in which all users must specify an index=clause in all searches be configured?
Set the authorize.conf setting: srchIndexesDefault to no value.
Set the authorize.conf setting: srchFilter to no value.
Set the authorize.conf setting: srchIndexesAllowed to no value.
Set the authorize.conf setting: srchJobsQuota to no value.
In which of the following scenarios should base configurations be used to provide consistent, repeatable, and supportable configurations?
For non-production environments to keep their configurations in sync.
To ensure every customer has exactly the same base settings.
To provide settings that do not need to be customized to meet customer requirements.
To provide settings that can be customized to meet customer requirements.
Data can be onboarded using apps, Splunk Web, or the CLI.
Which is the PS preferred method?
Which is the PS preferred method?
Create UDP input port 9997 on a UF.
Use the add data wizard in Splunk Web.
Use the inputs.conf file.
Use a scripted input to monitor a log file.
Which of the following statements applies to indexer discovery?
The Cluster Master (CM) can automatically discover new indexers added to the cluster.
Forwarders can automatically discover new indexers added to the cluster.
Deployment servers can automatically configure new indexers added to the cluster.
Search heads can automatically discover new indexers added to the cluster.
The data in Splunk is now subject to auditing and compliance controls. A customer would like to ensure that at least one year of logs are retained for both
Windows and Firewall events. What data retention controls must be configured?
Windows and Firewall events. What data retention controls must be configured?
MaxTotalDataSizeMB and frozenTimePeriodInSecs
ColdToFrozenDir and coldToFrozenScript
Splunk Volume and maxTotalDataSizMB
Splunk Volume and frozenTimePeriodInSecs
What happens when an index cluster peer freezes a bucket?
All indexers with a copy of the bucket will delete it.
The cluster master will ensure another copy of the bucket is made on the other peers to meet the replication settings.
The cluster master will no longer perform fix-up activities for the bucket.
All indexers with a copy of the bucket will immediately roll it to frozen.
A customer has the following Splunk instances within their environment: An indexer cluster consisting of a cluster master/master node and five clustered indexers, two search heads (no search head clustering), a deployment server, and a license master. The deployment server and license master are running on their own single-purpose instances. The customer would like to start using the Monitoring Console (MC) to monitor the whole environment.
On the MC instance, which instances will need to be configured as distributed search peers by specifying them via the UI using the settings menu?
On the MC instance, which instances will need to be configured as distributed search peers by specifying them via the UI using the settings menu?
Just the cluster master/master node.
Indexers, search heads, deployment server, license master, cluster master/master node.
Search heads, deployment server, license master, cluster master/master node
Deployment server, license master
What does Splunk do when it indexes events?
Extracts the top 10 fields.
Extracts metadata fields such as host, source, sourcetype.
Performs parsing, merging, and typing processes on universal forwarders.
Create report acceleration summaries.
What is the default push mode for a search head cluster deployer app configuration bundle?
Full
Merge_to_default
Default_only
Local_only
In which of the following scenarios is a subsearch the most appropriate?
When joining results from multiple indexes.
When dynamically filtering hosts.
When filtering indexed fields.
When joining multiple large datasets.
A customer has implemented their own Role Based Access Control (RBAC) model to attempt to give the Security team different data access than the Operations team by creating two new Splunk roles "security" and "operations". In the srchIndexesAllowed setting of authorize.conf, they specified the network index under the security role and the operations index under the operations role. The new roles are set up to inherit the default user role.
If a new user is created and assigned to the operations role only, which indexes will the user have access to search?
If a new user is created and assigned to the operations role only, which indexes will the user have access to search?
Operations, network
Operations
No Indexes
Operations, network, _internal, _audit
A customer would like Splunk to delete files after they've been ingested. The Universal Forwarder has read/write access to the directory structure. Which input type would be most appropriate to use in order to ensure files are ingested and then deleted afterwards?
Script
Batch
Monitor
Fschange
A customer has three users and is planning to ingest 250GB of data per day. They are concerned with search uptime, can tolerate up to a two-hour downtime for the search tier, and want advice on single search head versus a search head cluster. (SHC). Which recommendation is the most appropriate?
The customer should deploy two active search heads behind a load balancer to support HA.
The customer should deploy a SHC with a single member for HA; more members can be added later.
The customer should deploy a SHC, because it will be required to support the high volume of data.
The customer should deploy a single search head with a warm standby search head and an rsync process to synchronize configurations.
A customer is having issues with truncated events greater than 64K. What configuration should be deployed to a universal forwarder (UF) to fix the issue?
EVENT_BREAKER_ENABLE and EVENT_BREAKER regular expression settings per sourcetype.
Global EVENT_BREAKER_ENABLE and EVENT_BREAKER regular expression settings.
Configure the best practice magic 6 or great 8 props.conf settings.
None. Splunk default configurations will process the events as needed; the UF is not causing truncation.
A new search head cluster is being implemented. Which is the correct command to initialize the deployer node without restarting the search head cluster peers?
$SPLUNK_HOME/bin/splunk apply shcluster-bundle -action stage
D. $SPLUNK_HOME/bin/splunk apply cluster-bundle -action stage
$SPLUNK_HOME/bin/splunk apply cluster-bundle
$SPLUNK_HOME/bin/splunk apply shcluster-bundle
A working search head cluster has been set up and used for 6 months with just the native/local Splunk user authentication method. In order to integrate the search heads with an external Active Directory server using LDAP, which of the following statements represents the most appropriate method to deploy the configuration to the servers?
Configure the integration in a base configuration app located in shcluster-apps directory on the search head deployer, then deploy the configuration to the search heads using the splunk apply shcluster-bundle command.
Log onto each search using a command line utility. Modify the authentication.conf and authorize.conf files in a base configuration app to configure the integration.
Configure the LDAP integration on one Search Head using the Settings > Access Controls > Authentication Method and Settings > Access Controls > Roles Splunk UI menus. The configuration setting will replicate to the other nodes in the search head cluster eliminating the need to do this on the other search heads.
On each search head, login and configure the LDAP integration using the Settings > Access Controls > Authentication Method and Settings > Access Controls > Roles Splunk UI menus.
In an environment that has Indexer Clustering, the Monitoring Console (MC) provides dashboards to monitor environment health. As the environment grows over time and new indexers are added, which steps would ensure the MC is aware of the additional indexers?
Using the MC setup UI, review and apply the changes.
No changes are necessary, the Monitoring Console has self-configuration capabilities.
Remove and re-add the cluster master from the indexer clustering UI page to add new peers, then apply the changes under the MC setup UI.
Each new indexer needs to be added using the distributed search UI, then settings must be saved under the MC setup UI.
A customer wants to migrate from using Splunk local accounts to use Active Directory with LDAP for their Splunk user accounts instead. Which configuration files must be modified to connect to an Active Directory LDAP provider?
Authentication.conf
Authentication.conf, authorize.conf, ldap.conf
Authentication.conf, ldap.conf
Authorize.conf, authentication.conf
What is required to setup the HTTP Event Collector (HEC)?
Each HEC input requires a unique name but token values can be shared.
Each HEC input requires an existing forwarder output group.
Each HEC input entry must contain a valid token.
Each HEC input requires a Source name field.
When monitoring and forwarding events collected from a file containing unstructured textual events, what is the difference in the Splunk2Splunk payload traffic sent between a universal forwarder (UF) and indexer compared to the Splunk2Splunk payload sent between a heavy forwarder (HF) and the indexer layer?
(Assume that the file is being monitored locally on the forwarder.)
(Assume that the file is being monitored locally on the forwarder.)
A. The payload format sent from the UF versus the HF is exactly the same. The payload size is identical because they're both sending 64K chunks.
The UF sends a stream of data containing one set of medata fields to represent the entire stream, whereas the HF sends individual events, each with their own metadata fields attached, resulting in a lager payload.
The UF will generally send the payload in the same format, but only when the sourcetype is specified in the inputs.conf and EVENT_BREAKER_ENABLE is set to true.
The HF sends a stream of 64K TCP chunks with one set of metadata fields attached to represent the entire stream, whereas the UF sends individual events, each with their own metadata fields attached.
The universal forwarder (UF) should be used whenever possible, as it is smaller and more efficient. In which of the following scenarios would a heavy forwarder (HF) be a more appropriate choice?
When a predictable version of Python is required.
When filtering 10%-15% of incoming events.
When monitoring a log file.
When running a script.
A non-ES customer has a concern about data availability during a disaster recovery event. Which of the following Splunk Validated Architectures (SVAs) would be recommended for that use case?
Topology Category Code: M4
Topology Category Code: M14
Topology Category Code: C13
Topology Category Code: C3
Which statement is correct?
In general, search commands that can be distributed to the search peers should occur as early as possible in a well-tuned search.
As a streaming command, streamstats performs better than stats since stats is just a reporting command.
When trying to reduce a search result to unique elements, the dedup command is the only way to achieve this.
Formatting commands such as fieldformat should occur as early as possible in the search to take full advantage of the often larger number of search peers.
Which event processing pipeline contains the regex replacement processor that would be called upon to run event masking routines on events as they are ingested?
Merging pipeline
Indexing pipeline
Typing pipeline
Parsing pipeline
What happens to the indexer cluster when the indexer Cluster Master (CM) runs out of disk space?
A warm standby CM needs to be brought online as soon as possible before an indexer has an outage.
The indexer cluster will continue to operate as long as no indexers fail.
If the indexer cluster has site failover configured in the CM, the second cluster master will take over.
The indexer cluster will continue to operate as long as a replacement CM is deployed within 24 hours.
In addition to the normal responsibilities of a search head cluster captain, which of the following is a default behavior?
The captain is not a cluster member and does not perform normal search activities.
The captain is a cluster member who performs normal search activities.
The captain is not a cluster member but does perform normal search activities.
The captain is a cluster member but does not perform normal search activities.
A customer would like to remove the output_file capability from users with the default user role to stop them from filling up the disk on the search head with lookup files. What is the best way to remove this capability from users?
Clone the default user role, remove the output_file capability, and assign it to the users.
Edit the default user role and remove the output_file capability.
Create a new role with the output_file capability that inherits the default user role and assign it to the users.
Create a new role without the output_file capability that inherits the default user role and assign it to the users.
A customer has 30 indexers in an indexer cluster configuration and two search heads. They are working on writing SPL search for a particular use-case, but are concerned that it takes too long to run for short time durations.
How can the Search Job Inspector capabilities be used to help validate and understand the customer concerns?
How can the Search Job Inspector capabilities be used to help validate and understand the customer concerns?
Search Job Inspector provides statistics to show how much time and the number of events each indexer has processed.
Search Job Inspector provides a Search Health Check capability that provides an optimized SPL query the customer should try instead.
Search Job Inspector cannot be used to help troubleshoot the slow performing search; customer should review index=_introspection instead.
The customer is using the transaction SPL search command, which is known to be slow.
Which of the following is the most efficient search?
A.

B.
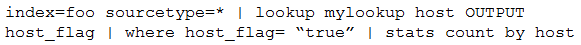
C.
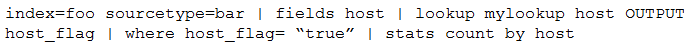
D.

A.
B.
C.
D.
A
B
C
D
In a large cloud customer environment with many (>100) dynamically created endpoint systems, each with a UF already deployed, what is the best approach for associating these systems with an appropriate serverclass on the deployment server?
Work with the cloud orchestration team to create a common host-naming convention for these systems so a simple pattern can be used in the serverclass.conf whitelist attribute.
Create a CSV lookup file for each severclass, manually keep track of the endpoints within this CSV file, and leverage the whitelist.from_pathname attribute in serverclass.conf.
Work with the cloud orchestration team to dynamically insert an appropriate clientName setting into each endpoint's local/deploymentclient.conf which can be matched by whitelist in serverclass.conf.
Using an installation bootstrap script run a CLI command to assign a clientName setting and permit serverclass.conf whitelist simplification.
The Splunk Validated Architectures (SVAs) document provides a series of approved Splunk topologies. Which statement accurately describes how it should be used by a customer?
Customer should look at the category tables, pick the highest number that their budget permits, then select this design topology as the chosen design.
Customers should identify their requirements, provisionally choose an approved design that meets them, then consider design principles and best practices to come to an informed design decision.
Using the guided requirements gathering in the SVAs document, choose a topology that suits requirements, and be sure not to deviate from the specified design.
Choose an SVA topology code that includes Search Head and Indexer Clustering because it offers the highest level of resilience.
Which of the following server roles should be configured for a host which indexes its internal logs locally?
Cluster master
Indexer
Monitoring Console (MC)
Search head
A customer is migrating their existing Splunk Indexer from an old set of hardware to a new set of indexers. What is the earliest method to migrate the system?
1. Add new indexers to the cluster as peers, in the same site (if needed). 2. Ensure new indexers receive common configuration. 3. Decommission old indexers (one at a time) to allow time for CM to fix/migrate buckets to new hardware. 4. Remove all the old indexers from the CM's list.
1. Add new indexers to the cluster as peers, to a new site. 2. Ensure new indexers receive common configuration from the CM. 3. Decommission old indexers (one at a time) to allow time for CM to fix/migrate buckets to new hardware. 4. Remove all the old indexers from the CM's list.
1. Add new indexers to the cluster as peers, in the same site. 2. Update the replication factor by +1 to Instruct the cluster to start replicating to new peers. 3. Allow time for CM to fix/migrate buckets to new hardware. 4. Remove all the old indexers from the CM's list.
1. Add new indexers to the cluster as new site. 2. Update cluster master (CM) server.conf to include the new available site. 3. Allow time for CM to fix/migrate buckets to new hardware. 4. Remove the old indexers from the CM's list.
When utilizing a subsearch within a Splunk SPL search query, which of the following statements is accurate?
Subsearches have to be initiated with the | subsearch command.
Subsearches can only be utilized with | inputlookup command.
Subsearches have a default result output limit of 10000.
There are no specific limitations when using subsearches. Suggested
A customer is using both internal Splunk authentication and LDAP for user management. If a username exists in both $SPLUNK_HOME/etc/passwd and LDAP, which of the following statements is accurate?
The internal Splunk authentication will take precedence.
Authentication will only succeed if the password is the same in both systems.
The LDAP user account will take precedence.
Splunk will error as it does not support overlapping usernames
When setting up a multisite search head and indexer cluster, which nodes are required to declare site membership?
Search head cluster members, deployer, indexers, cluster master
Search head cluster members, deployment server, deployer, indexers, cluster master
All splunk nodes, including forwarders, must declare site membership
Search head cluster members, indexers, cluster master
Which of the following is the most efficient search?
Index=www status=200 uri=/cart/checkout | append [search index = sales] | stats count, sum(revenue) as total_revenue by session_id | table total_revenue session_id
(index=www status=200 uri=/cart/checkout) OR (index=sales) | stats count, sum(revenue) as total_revenue by session_id | table total_revenue session_id
Index=www | append [search index = sales] | stats count, sum(revenue) as total_revenue by session_id | table total_revenue session_id
(index=www) OR (index=sales) | search (index=www status=200 uri=/cart/checkout) OR (index=sales) | stats count, sum (revenue) as total_revenue by session_id | table total_revenue session_id
A Splunk Index cluster is being installed and the indexers need to be configured with a license master. After the customer provides the name of the license master, what is the next step?
Enter the license master configuration via Splunk web on each indexer before disabling Splunk web.
Update /opt/splunk/etc/master-apps/_cluster/default/server.conf on the cluster master and apply a cluster bundle.
Update the Splunk PS base config license app and copy to each indexer.
Update the Splunk PS base config license app and deploy via the cluster master.
When can the Search Job Inspector be used to debug searches?
If the search has not expired.
If the search is currently running.
If the search has been queued.
If the search has expired.
Where are Splunk Data Model Acceleration (DMA) summaries stored?
In tstatsHomePath
In the .tsidx files.
In summaryHomePath
In journal.gz
Which of the following statements is true, as it pertains to search head clustering (SHC)?
SHC is supported on AIX, Linux, and Windows operating systems.
Maximum number of nodes for a SHC is 10.
SHC members must run on the same hardware specifications.
Minimum number of nodes for a SHC is 5.
A customer is using regex to whitelist access logs and secure logs from a web server, but only the access logs are being ingested. Which troubleshooting resource would provide insight into why the secure logs are not being ingested?
List monitor
Oneshot
Btprobe
Tailingprocessor
As data enters the indexer, it proceeds through a pipeline where event processing occurs. In which pipeline does line breaking occur?
Indexing
Typing
Merging
Parsing
A customer has a network device that transmits logs directly with UDP or TCP over SSL. Using PS best practices, which ingestion method should be used?
Open a TCP port with SSL on a heavy forwarder to parse and transmit the data to the indexing tier.
Open a UDP port on a universal forwarder to parse and transmit the data to the indexing tier.
Use a syslog server to aggregate the data to files and use a heavy forwarder to read and transmit the data to the indexing tier.
Use a syslog server to aggregate the data to files and use a universal forwarder to read and transmit the data to the indexing tier.
Which command is most efficient in finding the pass4SymmKey of an index cluster?
Find / -name server.conf -print | grep pass4SymKey
$SPLUNK_HOME/bin/splunk search | rest splunk_server=local /servicesNS/-/unhash_app/storage/passwords
$SPLUNK_HOME/bin/splunk btool server list clustering | grep pass4SymmKey
$SPLUNK_HOME/bin/splunk btool clustering list clustering --debug | grep pass4SymmKey
Report acceleration has been enabled for a specific use case. In which bucket location is the corresponding CSV file located?
ThawedPath
SummaryHomePath
TstatsHomePath
HomePath, coldPath
When adding a new search head to a search head cluster (SHC), which of the following scenarios occurs?
The new search head connects to the deployer and pulls the most recently deployed bundle. It then connects to the captain and replays any recent configuration changes to bring it up to date.
The new search head connects to the captain and pulls the most recently deployed bundle. It then connects to the deployer and replays any recent configuration changes to bring it up to date.
The new search head connects to the deployer and replays any recent configuration changes to bring it up to date.
The new search head connects to the captain and replays any recent configuration changes to bring it up to date.
In the diagrammed environment shown below, the customer would like the data read by the universal forwarders to set an indexed field containing the UF's host name. Where would the parsing configurations need to be installed for this to work?
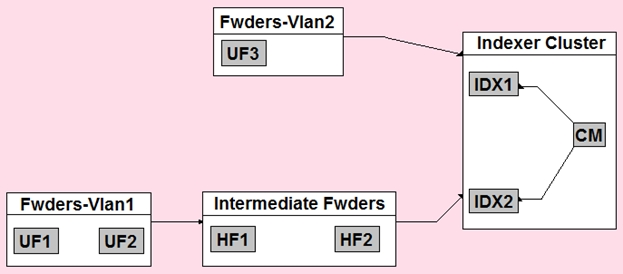
All universal forwarders.
Only the indexers.
All heavy forwarders.
On all parsing Splunk instances.
As a best practice which of the following should be used to ingest data on clustered indexers?
Monitoring (via a process), collecting data (modular inputs) from remote systems/applications
Modular inputs, HTTP Event Collector (HEC), inputs.conf monitor stanza
Actively listening on ports, monitoring (via a process), collecting data from remote systems/applications
Splunktcp, splunktcp-ssl, HTTP Event Collector (HEC)
хз тут
A new single-site three indexer cluster is being stood up with replication_factor:2, search_factor:2. At which step would the Indexer Cluster be classed as "˜Indexing Ready' and be able to ingest new data?
Step 1: Install and configure Cluster Master (CM)/Master Node with base clustering stanza settings, restarting CM.
Step 2: Configure a base app in etc/master-apps on the CM to enable a splunktcp input on port 9997 and deploy index creation configurations.
Step 3: Install and configure Indexer 1 so that once restarted, it contacts the CM, download the latest config bundle.
Step 4: Indexer 1 restarts and has successfully joined the cluster.
Step 5: Install and configure Indexer 2 so that once restarted, it contacts the CM, downloads the latest config bundle
Step 6: Indexer 2 restarts and has successfully joined the cluster.
Step 7: Install and configure Indexer 3 so that once restarted, it contacts the CM, downloads the latest config bundle.
Step 8: Indexer 3 restarts and has successfully joined the cluster.
Step 1: Install and configure Cluster Master (CM)/Master Node with base clustering stanza settings, restarting CM.
Step 2: Configure a base app in etc/master-apps on the CM to enable a splunktcp input on port 9997 and deploy index creation configurations.
Step 3: Install and configure Indexer 1 so that once restarted, it contacts the CM, download the latest config bundle.
Step 4: Indexer 1 restarts and has successfully joined the cluster.
Step 5: Install and configure Indexer 2 so that once restarted, it contacts the CM, downloads the latest config bundle
Step 6: Indexer 2 restarts and has successfully joined the cluster.
Step 7: Install and configure Indexer 3 so that once restarted, it contacts the CM, downloads the latest config bundle.
Step 8: Indexer 3 restarts and has successfully joined the cluster.
Step 2
Step 4
Step 6
Step 8
Where does the bloomfilter reside?
$SPLUNK_HOME/var/lib/splunk/indexfoo/db/db_1553504858_1553504507_8
$SPLUNK_HOME/var/lib/splunk/indexfoo/db/db_1553504858_1553504507_8/*.tsidx
$SPLUNK_HOME/var/lib/splunk/fishbucket
$SPLUNK_HOME/var/lib/splunk/indexfoo/db/db_1553504858_1553504507_8/rawdata
A customer has a multisite cluster (two sites, each site in its own data center) and users experiencing a slow response when searches are run on search heads located in either site. The Search Job Inspector shows the delay is being caused
by search heads on either site waiting for results to be returned by indexers on the opposing site. The network team has confirmed that there is limited bandwidth available between the two data centers, which are in different geographic
locations.
Which of the following would be the least expensive and easiest way to improve search performance?
by search heads on either site waiting for results to be returned by indexers on the opposing site. The network team has confirmed that there is limited bandwidth available between the two data centers, which are in different geographic
locations.
Which of the following would be the least expensive and easiest way to improve search performance?
Configure site_search_factor to ensure a searchable copy exists in the local site for each search head
Move all indexers and search heads in one of the data centers into the same site
. Install a network pipe with more bandwidth between the two data centers.
Set the site setting on each indexer in the server.conf clustering stanza to be the same for all indexers regardless of site.
A customer with a large distributed environment has blacklisted a large lookup from the search bundle to decrease the bundle size using distsearch.conf. After this change, when running searches utilizing the lookup that was blacklisted they see error messages in the Splunk Search UI stating the lookup file does not exist. What can the customer do to resolve the issue?
The search needs to be modified to ensure the lookup command specifies parameter local=true.
The blacklisted lookup definition stanza needs to be modified to specify setting allow_caching=true.
The search needs to be modified to ensure the lookup command specified parameter blacklist=false.
The lookup cannot be blacklisted; the change must be reverted.
Consider the search shown below.

What is this search's intended function?
What is this search's intended fun
To return all the web_log events from the web index that occur two hours before and after the most recent high severity, denied event found in the firewall index.
To find all the denied, high severity events in the firewall index, and use those events to further search for lateral movement within the web index.
To return all the web_log events from the web index that occur two hours before and after all high severity, denied events found in the firewall index.
To search the firewall index for web logs that have been denied and are of high severity.
When using SAML, where does user authentication occur?
Splunk generates a SAML assertion that authenticates the user.
The Service Provider (SP) decodes the SAML request and authenticates the user.
The Identity Provider (IDP) decodes the SAML request and authenticates the user
The Service Provider (SP) generates a SAML assertion that authenticates the user.
{"name":"Core Consultant Prep Quiz", "url":"https://www.quiz-maker.com/QPREVIEW","txt":"How does Monitoring Console (MC) initially identify the server role(s) of a new Splunk Instance?, A customer has asked for a five-node search head cluster (SHC) but does not have the storage budget to use a replication factor greater than 2. They would like to understand what might happen in terms of the users' ability to view historic scheduled search results if they log onto a search head that doesn't contain one of the 2 copies of a given search artifact. Which of the following statements best describes what would happen in this scenario?, Monitoring Console (MC) health check configuration items are stored in which configuration file?","img":"https://www.quiz-maker.com/3012/images/ogquiz.png"}
More Quizzes
Psychology Test
1780
Adobe Photoshop Skill Test 2023 Set01
40200
Zanieczyszczenia I ochrona środowiska!
40200
Kpop
940
Free EU Capitals
201021886
Think You Know Rocks? Try Our Types of Rocks Now!
201037653
Law of Talos: How Well Do You Know Karl? Try Now!
201052001
Free Communication Skills Test - How Clear Is Your Message?
201050817
Free Gustar Practice
201024833
Free Conics Test
201021886
Free Food Insecurity Knowledge Test
201022708
Free Division Arrays Worksheets
201021886